Deploying and Running Argo Workflows for AI/ML on OpenShift
Table of Contents
AI/ML OCP Tooling - This article is part of a series.
Synopsis #
In this post, we will explore the role of Argo Workflows in managing and automating AI/ML tasks on OpenShift. We’ll cover what Argo Workflows is, how it fits into our AI/ML ecosystem, and how you can get started with it.

Introduction #
Argo Workflows is a Kubernetes-native workflow engine for orchestrating parallel jobs on Kubernetes. It’s designed to handle complex, data-intensive, and compute-intensive tasks - making it ideal for AI/ML workloads.
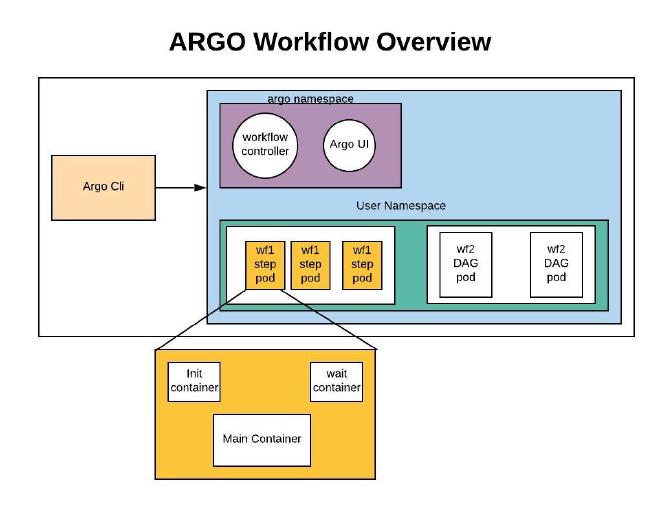
Argo Workflows and AI/ML #
Argo Workflows provides a number of features that are especially beneficial for AI/ML workloads:
- Pipeline Orchestration: Argo allows you to define complex workflows where multiple tasks are executed in sequence or in parallel.
- Artifact Management: Argo supports passing artifacts (like data or models) between tasks in a workflow. This is particularly useful for ML workflows where the output of one stage (e.g., model training) is the input for another stage (e.g., model evaluation).
- Integration with Kubernetes: Being Kubernetes-native, Argo Workflows can leverage features like scalability and fault tolerance provided by Kubernetes.
Deploying Argo Workflows on OpenShift #
Let’s look at an example of deploying Argo Workflows on an OpenShift cluster:
Install the Argo Workflows Operator from the OperatorHub in the OpenShift web console.
Create an
ArgoCDinstance:
apiVersion: argoproj.io/v1alpha1
kind: ArgoCD
metadata:
name: argocd
namespace: argocd
spec:
server:
route:
enabled: true
Setting Up an Initial Argo Workflow Pipeline #
With Argo Workflows installed, you can define workflows using the Workflow custom resource. Each Workflow consists of a series of steps, which can run scripts, commands, or even other Workflows.
Here’s an example of a basic ML workflow pipeline with Argo:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: ml-pipeline-
spec:
entrypoint: ml-pipeline
templates:
- name: ml-pipeline
steps:
- - name: pre-processing
template: python-script
arguments:
parameters:
- name: script
value: |
# Python script for data pre-processing
- - name: model-training
template: python-script
arguments:
parameters:
- name: script
value: |
# Python script for model training
- - name: model-evaluation
template: python-script
arguments:
parameters:
- name: script
value: |
# Python script for model evaluation
- name: python-script
inputs:
parameters:
- name: script
script:
image: python:3.7
command: [python]
source: |
{{inputs.parameters.script}}
This workflow consists of three steps: data pre-processing, model training, and model evaluation. Each step runs a Python script in a Python 3.7 Docker container.
Conclusion #
Argo Workflows offers a powerful, flexible way to manage your AI/ML workloads on OpenShift. Its pipeline orchestration, artifact management, and deep integration with Kubernetes make it an ideal choice for complex ML tasks.
References #
- Argo Workflows Documentation
- Argo Workflows Operator on OperatorHub
- AI/ML pipelines using Open Data Hub and Kubeflow on Red Hat OpenShift | Red Hat Developer