Leveraging ODF for AI Workloads on OpenShift
Table of Contents
AI/ML OCP Tooling - This article is part of a series.
Synopsis #
Welcome to another deep dive into OpenShift’s capabilities for handling AI and ML workloads. In this post, we’ll focus on the OpenShift Data Foundation (ODF) and how it can serve as a robust storage solution for your AI/ML applications.
Introduction #
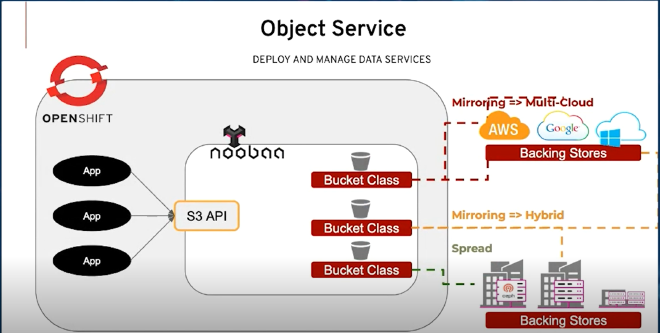
OpenShift Data Foundation (ODF), previously known as OpenShift Container Storage (OCS), is a software-defined storage solution designed for cloud-native applications on OpenShift. It provides a unified data platform for block, file, and object storage.
Technical Overview of ODF #
ODF leverages various open-source technologies including Ceph/Rook for persistent storage and NooBaa for multi-cloud gateway services. It’s tightly integrated with OpenShift, allowing you to manage storage just like any other OpenShift resource.
With ODF, you can dynamically provision Persistent Volume Claims (PVCs) for your applications, enabling on-demand, scalable storage. This feature is particularly useful for AI/ML workloads that might require significant storage resources for model training and inference.
Why ODF for AI/ML? #
ODF’s dynamic provisioning and scalability align perfectly with the variable nature of AI/ML workloads. The ability to quickly scale up or down based on workload requirements allows for optimal resource utilization.
ODF also supports high I/O operations, essential for AI/ML model training. It’s recommended to have SSDs or NVMe drives for your ODF nodes to ensure fast disk speeds. The exact hardware requirements might vary based on the size and complexity of your AI/ML workloads.
Configuration Example: Utilizing ODF for LLM Model Training #
To illustrate, let’s see how to utilize a pre-deployed ODF cluster for storage when training a Large Language Model (LLM) with Kubeflow on OpenShift.
- Create a
PersistentVolumeClaimfor your training job:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: model-training-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
storageClassName: ocs-storagecluster-ceph-rbd
- Use this PVC in your Kubeflow
TFJob:
apiVersion: "kubeflow.org/v1"
kind: "TFJob"
metadata:
name: "llm-training-job"
spec:
tfReplicaSpecs:
Worker:
replicas: 4
restartPolicy: OnFailure
template:
spec:
containers:
- name: tensorflow
image: <your-tensorflow-image>
volumeMounts:
- mountPath: "/data"
name: model-training-pvc
volumes:
- name: model-training-pvc
persistentVolumeClaim:
claimName: model-training-pvc
This configuration runs a distributed TensorFlow training job for the LLM, using the ODF-provided PVC for storage.
Alternatives to ODF #
While ODF is a robust solution for AI/ML workloads on OpenShift, it’s not the only option. Here’s a brief comparison with three alternatives:
1. Local Storage Operator #
- Pros: High performance, supports raw block access.
- Cons: Not as scalable, doesn’t support dynamic provisioning.
2. NFS #
- Pros: Easy to set up, supports ReadWriteMany (RWX) access mode.
- Cons: Lower performance compared to other solutions, not ideal for large-scale deployments.
3. Cloud Storage (AWS EBS, GCE Persistent Disk, Azure Disk) #
- Pros: Managed service, easy to use, supports dynamic provisioning.
- Cons: Performance and cost can vary, dependent on the cloud provider.
Conclusion #
OpenShift Data Foundation is a versatile and powerful storage solution for AI/ML workloads on OpenShift. Its dynamic provisioning, scalability, and support for high I/O operations make it ideal for such applications. However, depending on your specific requirements, other storage solutions may also be suitable.
References #
- OpenShift Documentation
- OpenShift Data Foundation Documentation
- Kubeflow Documentation
- Open Data Hub Documentation