OpenShift Serverless: A Comparison of Event Sources
Table of Contents
Serverless Servers - This article is part of a series.
Introduction #
Welcome back to MeatyBytes.io! In our ongoing exploration of OpenShift Serverless, we’ve discussed how to deploy serverless applications and how to process events in real-time. Today, we’re going to delve into a key feature of OpenShift Serverless: Knative Sources.
Knative Event Sources are objects that generate events that are consumed by Knative Services. There are several types of Event Sources, but today we’ll focus on two commonly used ones, especially in OpenShift Serverless: APIServerSource and KafkaSource.
In this post, we’ll define what these sources are, discuss when you might use each of them, and provide detailed configurations for using each in a cluster.
Let’s get started!
What are APIServerSource and KafkaSource? #
APIServerSource is a Knative event source that can be used to watch for changes to Kubernetes resources and trigger a Knative Service when these changes occur. This is useful for automating tasks in response to changes in your cluster, such as scaling workloads or updating configurations.
KafkaSource is a Knative event source that can be used to consume messages from a Kafka topic and trigger a Knative Service. This is useful for processing streaming data in real-time, such as logs, metrics, or user activity data.
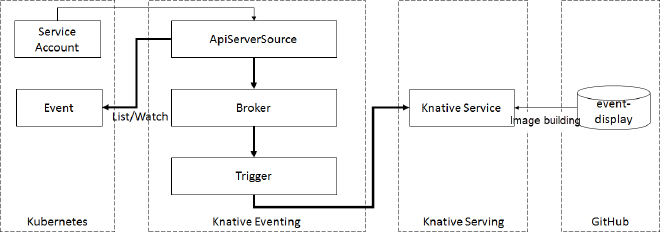
When to Use APIServerSource vs KafkaSource #
The choice between APIServerSource and KafkaSource depends on your specific use case:
- Use APIServerSource when you want to react to changes in your Kubernetes cluster: If you need to automate tasks in response to changes in your cluster,
APIServerSourceis a great choice. For example, you might useAPIServerSourceto trigger a backup whenever a new PersistentVolumeClaim (PVC) is created. - Use KafkaSource when you need to process streaming data: If you have a stream of data that you need to process in real-time,
KafkaSourceis the way to go. For example, you might useKafkaSourceto analyze logs or metrics as they’re generated.
Configuring APIServerSource #
Here’s a sample YAML configuration for an APIServerSource that watches for changes to Pod resources and triggers a Knative Service named meaty-service, both pre-configured:
apiVersion: sources.knative.dev/v1
kind: ApiServerSource
metadata:
name: pod-source
namespace: default
spec:
serviceAccountName: default
mode: Resource
resources:
- apiVersion: v1
kind: Pod
controller: true
sink:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: meaty-service
This configuration creates an APIServerSource that watches for changes to Pod resources in the default namespace and sends events to the meaty-service service.
Configuring KafkaSource #
Here’s a sample YAML configuration for a KafkaSource that consumes messages from a Kafka topic named meaty-topic and triggers a Knative Service named meaty-service, both pre-configured:
apiVersion: sources.knative.dev/v1beta1
kind: KafkaSource
metadata:
name: kafka-source
namespace: default
spec:
consumerGroup: my-group
bootstrapServers:
- my-cluster-kafka-bootstrap.kafka.svc:9092
topics:
- meaty-topic
sink:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: meaty-service
This configuration creates a KafkaSource that consumes messages from the meaty-topic Kafka topic and sends events to the meaty-service service.
Conclusion #
Both APIServerSource and KafkaSource are powerful tools for triggering serverless applications in response to events. By understanding the strengths and use cases of each source, you can choose the right tool for your needs and make the most of OpenShift Serverless.
As always, if you have any questions or run into any issues, don’t hesitate to reach out. Happy coding!
References #
For additional reading, check out the following resources:
- Knative Documentation
- OpenShift Serverless Documentation
- Event sources overview | Serverless
- Knative Eventing Sources Documentation
- Apache Kafka Documentation